1. Dag: dags_seoul_api_RealtimeCityAir
(1). "RealtimeCityAir_status_sensor": 서울시 공공데이터 포털에 현재 시간의 데이터가 정상적으로 업데이트되었는지 확인함, 정상적으로 업로드되지 않았다면 10분마다 업데이트 상태를 확인하고 다음 task로 넘어가지 않도록 대기함
(2). "RealtimeCityAir_status_to_csv": sensor에서 정상적으로 데이터가 업데이트 되었음을 확인하면, 데이터를 받고 csv 파일로 저장
(3). "insrt_postgres": csv 파일로 저장된 데이터를 postgres에 bulk load

2. dags와 plugins의 파일
▪ dags: Airflow의 DAG 파일이 저장되는 디렉터리로, 데이터 파이프라인의 실행 흐름 및 스케줄을 정의
▪ plugins: DAG에서 사용하는 사용자 정의 Hook, Operator, Sensor 등을 저장하는 디렉터리
SeoulRealtimeCityAir
├───dags
│ └───dags_seoul_api_RealtimeCityAir.py
├───plugins
│ ├───hooks
│ │ └───custom_postgres_hook.py
│ ├───operators
│ │ └───seoul_api_to_csv_operator.py
│ └───sensors
│ └───seoul_api_hour_sensor.py
├───.env
└───docker-compose.yaml(1). dags_seoul_api_RealtimeCityAir.py
▪ 서울시 권역별 실시간 대기환경 현황 데이터를 실제로 적재하기 위한 dag을 구성하고 있는 파일
▪ 매 시 정각에 dag이 실행되도록 스케줄링
from airflow import DAG
import pendulum
from airflow.operators.python import PythonOperator
from sensors.seoul_api_hour_sensor import SeoulApiHourSensor
from operators.seoul_api_to_csv_operator import SeoulApiToCsvOperator
from hooks.custom_postgres_hook import CustomPostgresHook
with DAG(
dag_id='dags_seoul_api_RealtimeCityAir',
schedule='0 * * * *',
start_date=pendulum.datetime(2023,12,26, tz='Asia/Seoul'),
catchup=False
) as dag:
'''서울시 권역별 실시간 대기환경 현황'''
RealtimeCityAir_status_sensor = SeoulApiHourSensor(
task_id='RealtimeCityAir_status_sensor',
dataset_nm='RealtimeCityAir',
base_dt_col='MSRDT',
hour_off=0,
poke_interval=600,
timeout = 600*6,
mode='reschedule'
)
RealtimeCityAir_status_to_csv = SeoulApiToCsvOperator(
task_id='RealtimeCityAir_status_to_csv',
dataset_nm='RealtimeCityAir',
path='/opt/airflow/files/RealtimeCityAir/',
file_name='RealtimeCityAir_{{data_interval_end.in_timezone("Asia/Seoul") | ds}}.csv'
)
def insrt_postgres(postgres_conn_id, tbl_nm, file_nm, **kwargs):
custom_postgres_hook = CustomPostgresHook(postgres_conn_id=postgres_conn_id)
custom_postgres_hook.bulk_load(table_name=tbl_nm, file_name=file_nm, delimiter=',', is_header=True, is_replace=True)
insrt_postgres = PythonOperator(
task_id='insrt_postgres',
python_callable=insrt_postgres,
op_kwargs={'postgres_conn_id': 'conn-db-postgres-custom',
'tbl_nm': 'RealtimeCityAir_{{data_interval_end.in_timezone("Asia/Seoul") | ds}}',
'file_nm':'/opt/airflow/files/RealtimeCityAir/RealtimeCityAir_{{data_interval_end.in_timezone("Asia/Seoul") | ds}}.csv'
}
)
RealtimeCityAir_status_sensor >> RealtimeCityAir_status_to_csv >> insrt_postgres(2). custom_postgres_hook.py
▪ csv파일 형태의 데이터를 postgres에 bulk load하기 위한 파일
from airflow.hooks.base import BaseHook
import psycopg2
import pandas as pd
class CustomPostgresHook(BaseHook):
def __init__(self, postgres_conn_id, **kwargs):
self.postgres_conn_id = postgres_conn_id
def get_conn(self):
airflow_conn = BaseHook.get_connection(self.postgres_conn_id)
self.host = airflow_conn.host
self.user = airflow_conn.login
self.password = airflow_conn.password
self.dbname = airflow_conn.schema
self.port = airflow_conn.port
self.postgres_conn = psycopg2.connect(host=self.host, user=self.user, password=self.password, dbname=self.dbname, port=self.port)
return self.postgres_conn
def bulk_load(self, table_name, file_name, delimiter: str, is_header: bool, is_replace: bool):
from sqlalchemy import create_engine
self.log.info('적재 대상파일:' + file_name)
self.log.info('테이블:'+table_name)
self.get_conn()
header = 0 if is_header else None # is_header = True면 0, False면 None
if_exists = 'replace' if is_replace else 'append' # is_replace = True면 replace, False면 append
file_df = pd.read_csv(file_name, header=header, delimiter=delimiter)
for col in file_df.columns:
try:
# string 문자열이 아닐 경우 continue
file_df[col] = file_df[col].str.replace('\r\n','') # 줄넘김 및 ^M 제거
self.log.info(f'{table_name}.{col}: 개행문자 제거')
except:
continue
self.log.info('적재 건수:'+str(len(file_df)))
uri = f'postgresql://{self.user}:{self.password}@{self.host}/{self.dbname}'
engine = create_engine(uri)
file_df.to_sql(name=table_name,
con=engine,
schema='public',
if_exists=if_exists,
index=False
)(3). seoul_api_to_csv_operaotor.py
▪ 공공데이터를 csv파일 형태로 저장하기 위한 파일
from airflow.models.baseoperator import BaseOperator
from airflow.hooks.base import BaseHook
import pandas as pd
class SeoulApiToCsvOperator(BaseOperator):
template_fields = ('endpoint', 'path','file_name','base_dt')
def __init__(self, dataset_nm, path, file_name, base_dt=None, **kwargs):
super().__init__(**kwargs)
self.http_conn_id = 'openapi.seoul.go.kr'
self.path = path
self.file_name = file_name
self.endpoint = '{{var.value.apikey_openapi_seoul_go_kr}}/json/' + dataset_nm
self.base_dt = base_dt
def execute(self, context):
import os
connection = BaseHook.get_connection(self.http_conn_id)
self.base_url = f'http://{connection.host}:{connection.port}/{self.endpoint}'
total_row_df = pd.DataFrame()
start_row = 1
end_row = 1000
while True:
self.log.info(f'시작:{start_row}')
self.log.info(f'끝:{end_row}')
row_df = self._call_api(self.base_url, start_row, end_row)
total_row_df = pd.concat([total_row_df, row_df])
if len(row_df) < 1000:
break
else:
start_row = end_row + 1
end_row += 1000
if not os.path.exists(self.path):
os.system(f'mkdir -p {self.path}')
if not os.path.exists(self.path+ '/' + self.file_name):
total_row_df.to_csv(self.path + '/' + self.file_name, mode='w', encoding='utf-8', index=False)
else:
total_row_df.to_csv(self.path + '/' + self.file_name, mode='a', encoding='utf-8', index=False, header=False)
def _call_api(self, base_url, start_row, end_row):
import requests
import json
headers = {'Content-Type': 'application/json',
'charset': 'utf-8',
'Accept': '*/*'
}
request_url = f'{base_url}/{start_row}/{end_row}/'
if self.base_dt is not None:
request_url = f'{base_url}/{start_row}/{end_row}/{self.base_dt}'
response = requests.get(request_url, headers)
contents = json.loads(response.text)
key_nm = list(contents.keys())[0]
row_data = contents.get(key_nm).get('row')
row_df = pd.DataFrame(row_data)
return row_df(4). seoul_api_hour_sensor.py
▪ 시간 단위로 업데이트되는 서울시 공공데이터가 정상적으로 업로드되어 있는지 확인하기 위한 sensor가 포함된 파일
from airflow.sensors.base import BaseSensorOperator
from airflow.hooks.base import BaseHook
class SeoulApiHourSensor(BaseSensorOperator):
template_fields = ('endpoint',)
def __init__(self, dataset_nm, base_dt_col, hour_off=0, **kwargs):
'''
dataset_nm: 서울시 공공데이터 포털에서 센싱하고자 하는 데이터셋 명
base_dt_col: 센싱 기준 컬럼 (YYYYMMDDHHmm 형태만 가능)
hour_off: 배치일 기준 생성여부를 확인하고자 하는 시간 차이를 입력 (기본값: 0)
'''
super().__init__(**kwargs)
self.http_conn_id = 'openapi.seoul.go.kr'
self.endpoint = '{{var.value.apikey_openapi_seoul_go_kr}}/json/' + dataset_nm + '/1/100' # 100건만 추출
self.base_dt_col = base_dt_col
self.hour_off = hour_off
def poke(self, context):
import requests
import json
from dateutil.relativedelta import relativedelta
connection = BaseHook.get_connection(self.http_conn_id)
url = f'http://{connection.host}:{connection.port}/{self.endpoint}'
self.log.info(f'request url:{url}')
response = requests.get(url)
contents = json.loads(response.text)
key_nm = list(contents.keys())[0]
row_data = contents.get(key_nm).get('row')
last_date = row_data[0].get(self.base_dt_col)
try:
import pendulum
last_date = pendulum.from_format(last_date, 'YYYYMMDDHHmm')
except:
from airflow.exceptions import AirflowException
AirflowException(f'{self.base_dt_col} 컬럼은 YYYYMMDDHHmm 형태가 아닙니다.')
search_ymd = (context.get('data_interval_end').in_timezone('Asia/Seoul') + relativedelta(hours=self.hour_off)).strftime('%Y-%m-%d %H:00')
search_ymd = pendulum.from_format(search_ymd, 'YYYY-MM-DD HH:mm')
if last_date >= search_ymd:
self.log.info(f'생성 확인(기준 날짜: {search_ymd} / API Last 날짜: {last_date})')
return True
else:
self.log.info(f'Update 미완료 (기준 날짜: {search_ymd} / API Last 날짜:{last_date})')
return False3. 적재 결과 확인하기
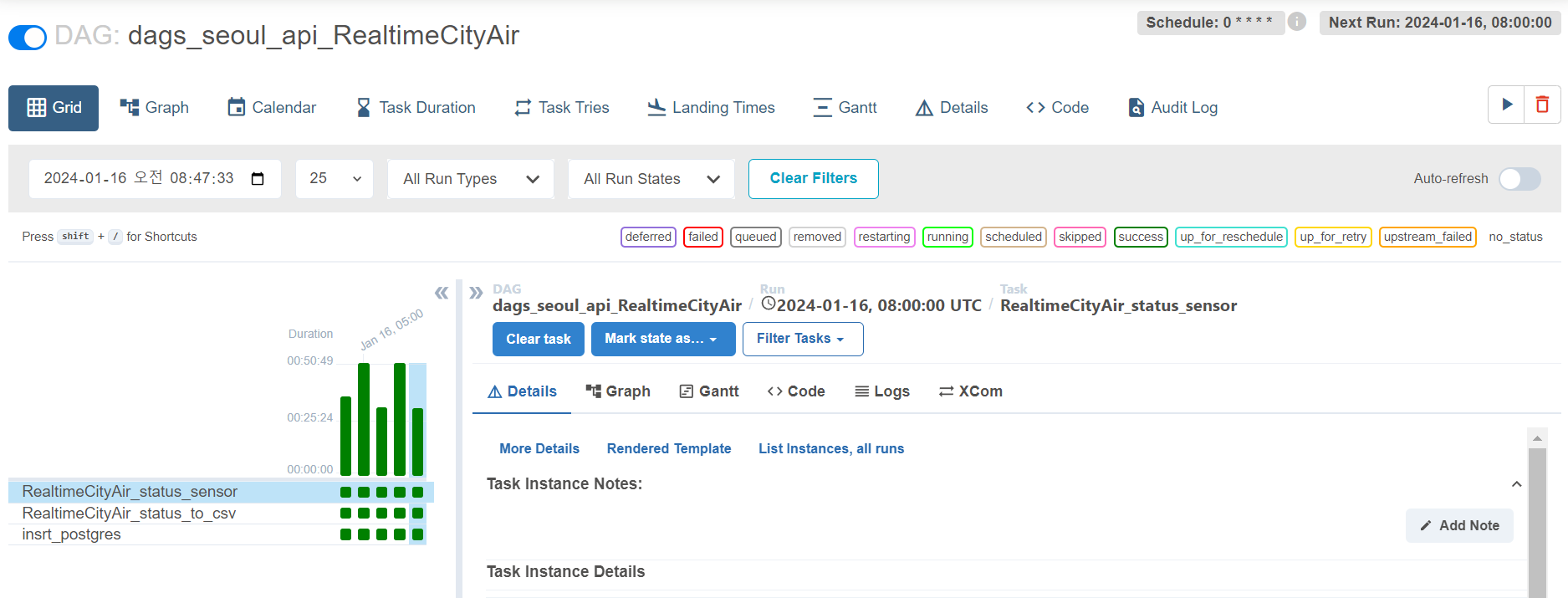
▪ Airflow webserver에 접속하여 dag 실행
▪ task 마다 실행 완료 시간이 차이가 나는데, 데이터가 정상적으로 업데이트되어 있지 않을 경우 대기하기 때문에 다음과 같이 차이가 발생한 것으로 보임, 대략 30분~50분 정도 걸렸음
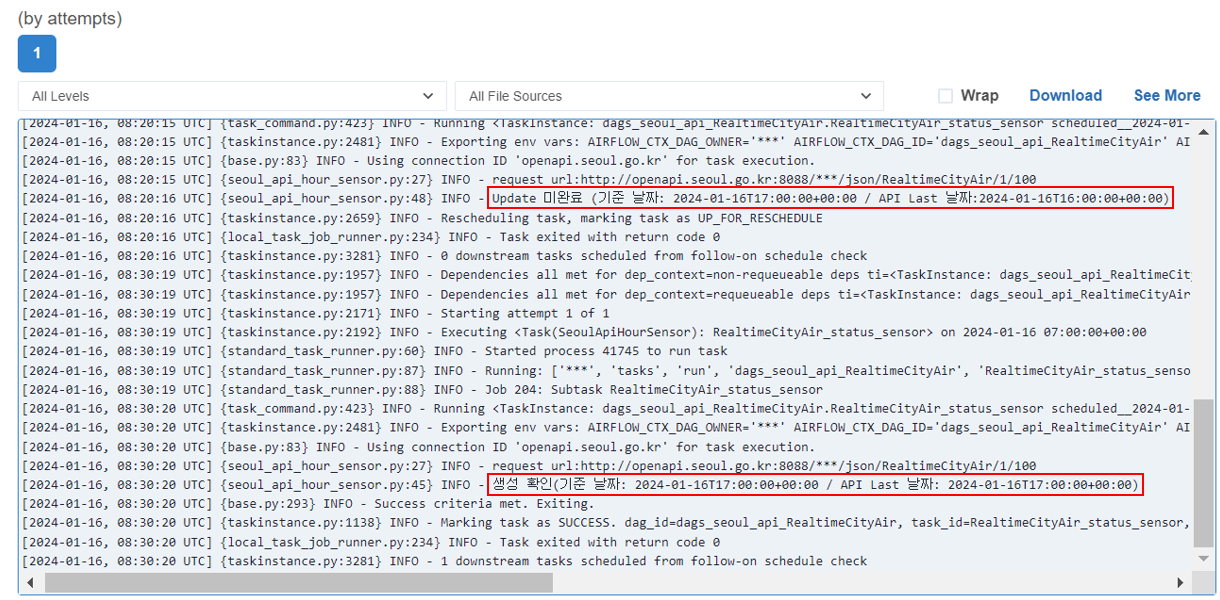
▪ sensor의 log를 확인해보면 미완료의 경우 API의 마지막 날짜와 기준 날짜가 다름
▪ 반대로 생성 확인에 성공한 경우 API의 마지막 날짜와 기준 날짜가 같음
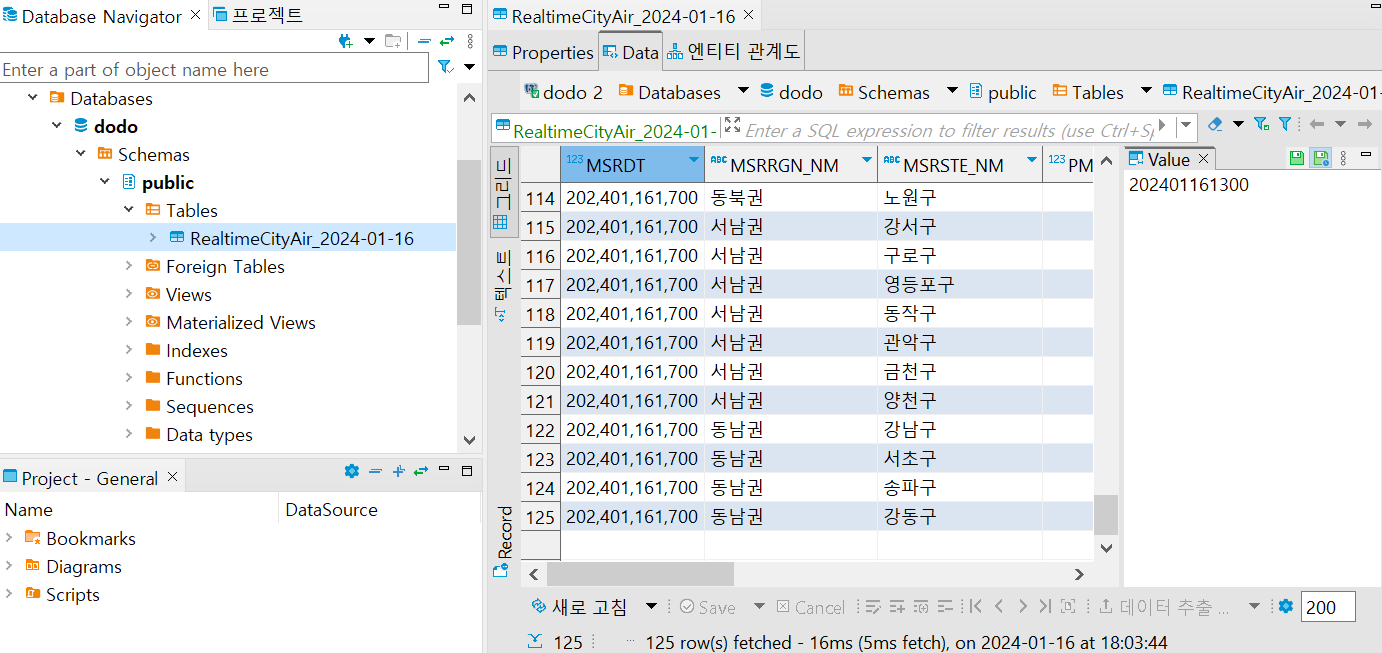
▪ DBeaver에 접속해 확인해보면 시간대 별로 데이터가 적재되었음
GitHub - dojun43/SeoulRealtimeCityAir: 서울시 대기현황 데이터 파이프라인 구축 프로젝트
서울시 대기현황 데이터 파이프라인 구축 프로젝트. Contribute to dojun43/SeoulRealtimeCityAir development by creating an account on GitHub.
github.com
'프로젝트 > 서울시 대기현황 데이터 적재 프로젝트' 카테고리의 다른 글
| [서울시 대기현황 데이터 적재 프로젝트] Streamlit으로 Dashboard 만들기 (4) (1) | 2024.09.26 |
|---|---|
| [서울시 대기현황 데이터 적재 프로젝트] Terraform으로 배포 환경 구성하기 (3) (1) | 2024.09.18 |
| [서울시 대기현황 데이터 적재 프로젝트] Airflow 환경 구성하기 (1) (0) | 2024.01.16 |